Magyar bioinformatikai konferenciák
Itt listázzuk a hazai, bioinformatikai témát is tartalmazó konferenciákat.






Az NGSchool egy, a bioinformatikai tudást terjeszteni kívánó közösség, amely minden évben nyári iskolát szervez. A programszervezés folyamatában várják a felmerülő ötleteket a nagyközönség részéről.

A Magyar Bioinformatikai Társaság tisztelettel meghívja tagjait a 2024. évi első közgyűlésére, amelynek ideje: 2024. május 10. péntek, 14 óra, helyszíne: 1117 Budapest, Magyar Tudósok körútja 2, földszinti kis előadó. Megjelenésére feltétlenül számítunk!
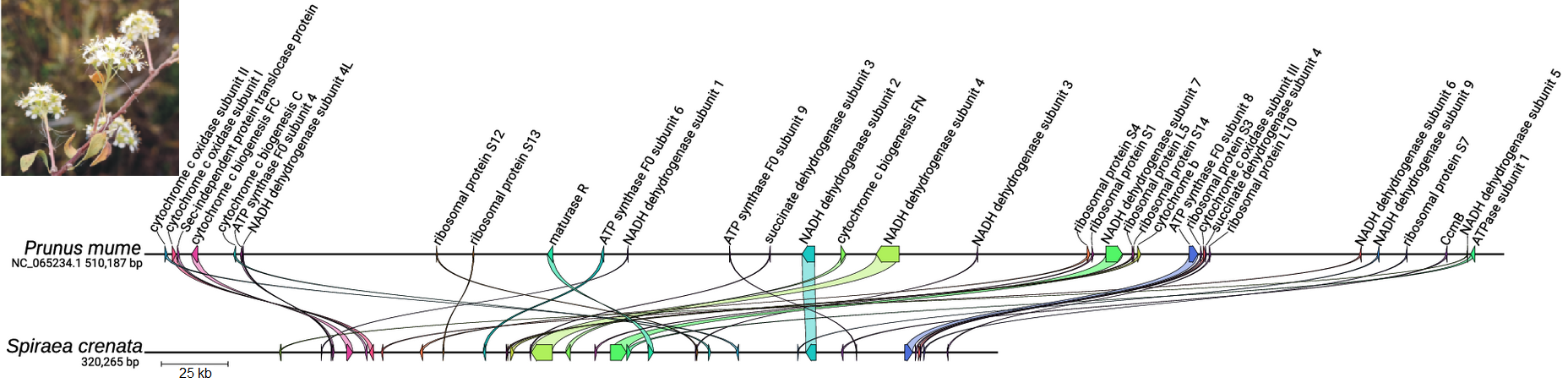
A közelmúltban jelent meg Dr. Sramkó Gábor ELIXIR vezető kutató irányításával készült közlemény, amelyben egy eukarióta, nem-modell növényfaj, a csipkés gyöngyvessző (a Spiraea crenata L.) teljes genomjának első feltérképezéséről olvashatunk. Ez az első Magyarországon összeszerelt nem-modell növényfaj genom.

Medikus és PhD hallgatók részvételével megkezdődött az angol nyelvű Klinikai Bioinformatika tárgy oktatása a Semmelweis Egyetem Bioinformatika Tanszékén.

Hazai intézetek, különböző tudományterületek képviselőinek jelentkezését várják az Ökológiai Kutatóközpont nyári rendezvényére a cikkben olvasható felhívás szerint.

A Dr. Garamszegi László Zsolt, ELIXIR vezető kutató irányításával készült tanulmányban a fenotípusos tulajdonságok additív genetikai varianciájának és öröklődőképességének számításakor felmerülő módszertani nehézségekről olvashatunk az örvös légykapó példáján.

Budapest, 2024. március 7. – Nők a Tudományban Kiválósági Díjjal ismerték el Dr. Lengyel Edina és Dr. Munkácsy Gyöngyi munkásságát, kiemelkedő tudományos teljesítményük, valamint a jövő kutatói generációját érintő mentorálási tevékenységük elismeréseként.

2024.03.06-án angol nyelvű tudományos vita során megvédte doktori címét Dr. Bartha Áron, a Semmelweis Egyetem Patológiai Tudományok Doktori Iskola hallgatója, aki Dr. Győrffy Balázs vezetése alatt végezte PhD munkáját.
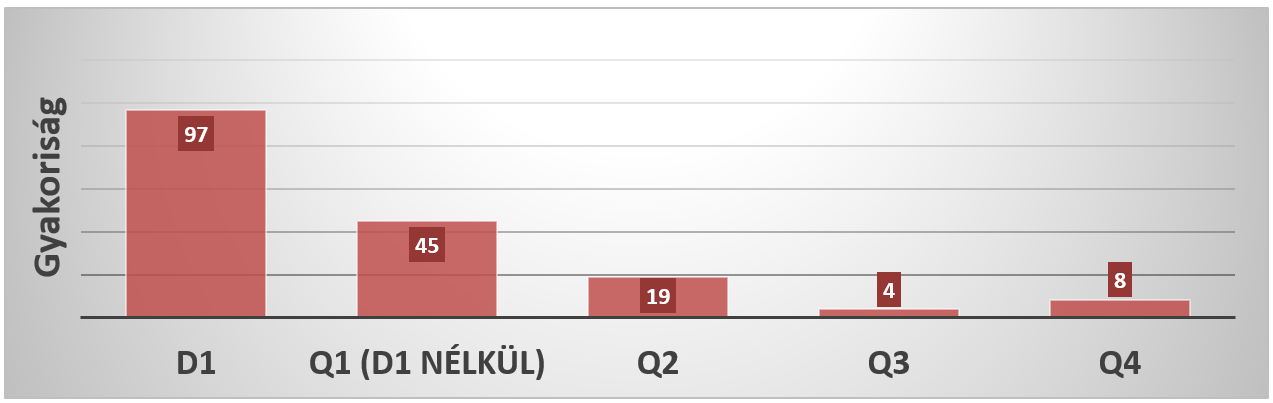
Az ELIXIR Magyarország kutatóinak közreműködésével 2023-ban 212 db cikk jelent meg hazai vagy nemzetközi tudományos folyóiratban, amelyek listája itt tekinthető meg.

Lépjen kapcsolatba velünk!
Először regisztrálni kell az ELIXIR Intranetre, majd ezen az oldalon lehet feliratkozni a levelező listák bármelyikére. Kb 1-2 nap átfutási idővel kell számolni.